Дорисовал схему усилителя для наушников. Схема, в‑общем, самая классическая — операционный усилитель и двухтактный выходной каскад на рабоче-крестьянских силовых транзисторах TIP29/TIP30. Берём любую книжку по электронике, например, того же Горовица-Хилла, и там всё можно найти.
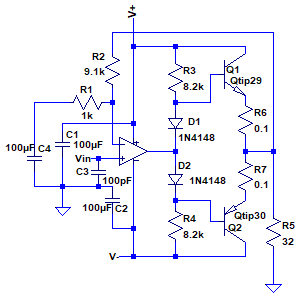
Схема питается от блока питания ±15V, и её можно использовать не только для наушников. Если немного пересчитать выходной каскад, она вполне может потянуть небольшой громкоговоритель, желательно, импедансом повыше (от 16 ом), и может в таком режиме выдавать около 2 ватт. Это, кстати, только кажется, что мало. При громкоговорителе с нормальной чувствительностью этого вполне достаточно, чтобы домашние начали орать, чтобы сделал потише =)
В конечном счёте максимальная выдаваемая данным усилителем мощность упирается в основном в ограничения операционного усилителя OPA134 и простого выходного каскада — питание максимум от ±18 вольт, выходное напряжение на ±2 вольта меньше напряжения питания, максимальный выдаваемый ОУ ток — 34 миллиампера, плюс падение в 0.7 вольт на каждом выходном транзисторе — и получается, что сильно больше этих самых двух ватт не выжмешь. Ну, если речь о том, чтобы слушать качественный сигнал.
Немного о самой схеме (это, скорее, заметки для себя, чтобы не забыть, как это всё рассчитывать). Коэффициент усиления обуславливается соотношением номиналов резисторов R2 и R1 в цепи отрицательной обратной связи и равен 1 + R2/R1, т.е. при данных номиналах он составляет около 10. Резистор R2 я сделаю переменным, крутилку выведу наружу и помечу как Gain. Конденсаторы C1 и C2 дополнительно стабилизируют питание (в окончательной схеме я их ещё дополнительно шунтирую мелкими керамическими или полиэстеровыми конденсаторами). Конденсатор C3 закорачивает наводки радиочастот на землю, чтобы не усиливать посторонние сигналы. Выходной тракт самый обычный — диоды D1 и D2 практически любые маломощные кремниевые, их задача только в том, чтобы загнать транзисторы Q1 и Q2 в линейный режим, иначе при переходе сигнала через ноль будут искажения. Не надо использовать мощные выпрямительные, германиевые или диоды Шоттки — у них падение напряжения будет другим, чем на базе у кремниевых транзисторов. Вдобавок их надо монтировать в контакте с самими транзисторами, на теплопроводящей пасте — таким образом будет обеспечена стабильность при нагреве. Значения резисторов R3 и R4 рассчитываются исходя из максимального тока, который будет выдаваться транзисторами. Я исходил из максимальной мощности в 1 ватт, для нагрузки в 32 ома (представленной резистором R5). По закону Ома это ток около 32 миллиампер. Делим это на коэффициент усиления по току транзисторов в 30 (мыслим консервативно). Получаем около 9k ом. Мыслим, опять же, консервативно, и ставим 8k2. Выходные резисторы R6 и R7 опять же, для дополнительной стабильности. Ну, и конденсатор C4 приводит коэффициент усиления схемы к нулю для сигналов постоянного тока.
При симуляции усилителя параметры КНИ очень впечатляющие:

А теперь попробуйте повторить это же самое на лампах, ага. Всё чисто ламповое (не гибридное) с КНИ менее 0.1% есть либо наглое враньё, либо замеряно в каких-то спецусловиях, не имеющих ничего общего с реальным миром.
Конечно, понятно, что это только симуляция, и она не учитывает, например, тепловой шум от резисторов (что тоже корёжит сигнал). Но по крайней мере, это служит хорошей аттестацией того, что дизайн как минимум, неплох.
Одно мне непонятно в программе LTSpice — её очень странный подход к расчёту тепловыделения. Она продолжает упорно считать, что при максимальной громкости транзистор Q1 будет рассеивать более 8 ватт. При этом напряжение, выдаваемое усилителем на нагрузку, составляет 20 вольт от гребня до гребня, или около 7 вольт среднеквадратичных. Соответственно, это ток в 220 миллиампер или 110 миллиампер на каждый транзистор. На транзисторе высаживается около 11.5 вольт, и его тепловыделение будет около 1.3 ватт (ток в базе я не буду учитывать — там копейки). Откуда восемь ватт — непонятно.
В заключение скажу, что для наушников данный усилитель — мягко говоря, очень избыточен. Чувствительность моих 950х Сонек составляет 106 децибел на милливатт. Т.е. выдав на них 10 милливатт я получу громкость как на концерте монстров рока, а с мощностью в 1 ватт я почти с гарантией оглохну =)))
Осталось запилить схему в том же Eagle, запулить печатную плату, собрать, и вперёд. Надеюсь, найду время.