Всё же как много я не знаю и не понимаю. Последний месяц-два изучаю методы измерения параметров качественности усиления звукового (и не только) сигнала.
Методов есть несколько, но про это в другой раз.
Основа в том, что чистый сигнал определённой частоты (например, 1 КГц) представляет собой синусоиду. Всё, что немного не синусоида, уже есть не чистый сигнал, а сумма сигналов, сумма синусоид. Даже меандр можно описать синусоидами — как функцию y(x) = sin(x) + sin (3x) / 3 + sin (5x) / 5 + .. + sin (nx) / n. Потому что меандр — это сумма синусоид основного сигнала и синусоид нечётных гармоник — то-есть, сигналов с частотой в 3, 5, 7 и так далее до бесконечности раз выше основной. Просто если речь идёт о звуковом сигнале, гармоники выше 19й слышны (как считается) уже не будут, так что меандр там получается не совсем полный, приблизительный.
Так вот если есть источник звукового сигнала, как узнать, насколько чистый там тон? Можно записать это в обыкновенный wav файл, а потом провести над полученным массивом данных математическое издевательство, называемое преобразованием Фурье. Пакетов для этого существует масса, можно взять бесплатный редактор Audacity, в нём есть спектральный анализ (преобразование Фурье это оно и есть).
Но, во-первых, я не ищу лёгкого пути, а во-вторых, мерять гармоники, долго их складывать и вставлять в формулу для расчёта КНИ я не хочу. Нехай электронный болван всё за меня считает, он на то и был куплен.
Так что нарисовал свою программу. Разумеется, на Питоне (на чём же ещё, не на Сях же рисовать). Благо есть модуль SciPy, в котором уже всё придумано, в том числе алгоритм быстрого преобразования Фурье (сиречь FFT).
Алгоритм FFT выдаёт гистограмму. По горизонтали — частота сигнала, по вертикали — его громкость. Примерно так слышит музыку человеческое ухо. Так вот выяснилось, что по умолчанию алгоритм выдаёт симметричную вокруг нуля герц картинку, то-есть, есть как положительная частота, так и отрицательная %) На этом месте я залип — как это, минус один килогерц?
Анализ файла с синусоидой 1 КГц выглядит так:
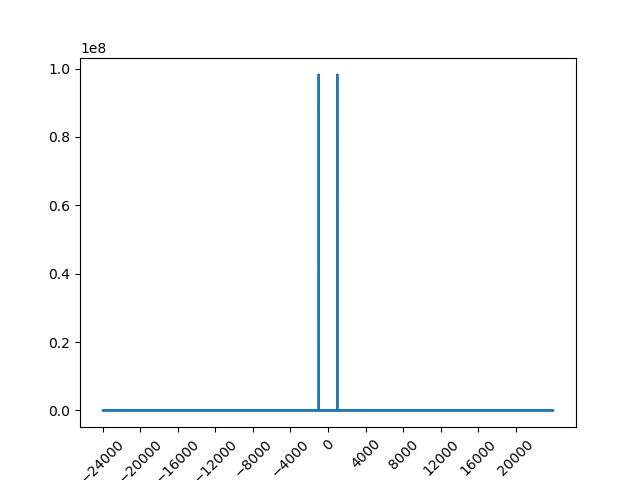
В принципе оно ведь логично — у синусоиды одна половинка имеет положительные значения от 0 до 1 (в военное время — до 4 =)), а другая — отрицательные, от 0 до ‑1. Соответственно, положительная частота — для того, что выше нуля, а отрицательная частота — для того, что ниже нуля. Правда, не совсем понятно, почему именно вот так — не было бы логичнее делать положительную и отрицательную амплитуды (громкости)?
Ещё менее понятным стало, когда я силой сгенерировал синусоиду с отрезанной верхушкой и сунул её в анализатор. Вот такую:
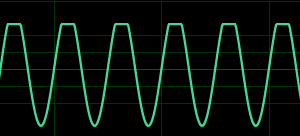
Я ожидал, что анализатор увидит туеву хучу гармоник с положительными частотами, и чистейший тон с отрицательными. Ан фиг — одни и те же гармоники были и слева и справа от нуля. Совсем непонятно, почему так. Вернее, конечно, понятно — сигнал это ВСЯ синусоида, от нуля до двух пи радиан, а не только её часть. Но тогда уже непонятно, зачем вообще городить огород с отрицательными и положительными частотами — не всё ли равно?
Плюнул, сменил алгоритм scipy.fftpack.fft на scipy.fftpack.rfft. rfft — это real fft, и отрицательных частот не выдаёт. Так намного понятнее.
Продолжаю изучать.







